

1- ELF Sections
In the previous part, I talked about ELF Section headers.
Now you are familiar with section headers and you saw that the section headers table has a special structure.
Sections contain all the information needed for linking a target object file in order to build a working executable.
But the sections haven’t any special structure. For example, as before, the string table section is a series of NULL-terminated strings. This section has its own structure. But the “.text” section is a series of bytes that are opcodes of the program and haven’t any special structure. So sections differ from each other in structure.
Now I want to describe some important sections that are common in all ELF files.
1-1 .init and .fini ELF sections
These sections contain executable codes that run before and after any other code in the binary executable
The codes in the .init section run before the main function and the codes in the .fini section run after the main function.
But there is an important tip that you should know about these sections. These sections in new Linux versions are deprecated. I describe it with an example. If you want to have a code that runs from the .init section, you can define a function in your code with the “constructor” attribute, and then the GCC compiler adds that function to the .init section for you and it runs before any other codes. Otherwise, you can define a function in your code with the “destructor” attribute, and then the GCC compiler adds that function to the .fini section for you and it runs after any other codes. But in a newer version of Linux, the .init_array and .fini_array are added. In these new changes, you can have multiple functions that can run before/after the main function.
I talk about it in the .init_array/.fini_array sections.
1-2 .init_array/.fini_array ELF sections
As said in the previous section, this section is an array that holds the addresses of those functions that should run before the main function. If you have multiple functions in your code with “constructor”, then at compile time, the compiler adds the addresses of these functions to the .init_array. Let’s see an example:
include <stdio.h>
static void before_main(void) attribute((constructor));
static void before_main2(void) attribute((constructor));
static void after_main(void) attribute((destructor));
static void after_main2(void) attribute((destructor));
static void before_main(void)
{
printf("This is init\n");
}
static void before_main2(void)
{
printf("This is init2\n");
}
static void after_main(void)
{
printf("This is fini\n");
}
static void after_main2(void)
{
printf("This is fini2\n");
}
int main()
{
printf("This is main\n");
}In this code, we have two functions with constructor and two functions with destructor attr. after that we compile it, examine it, and disassemble it with objdump to see all codes of this binary.
$ objdump a.out -M intel -d
0000000000001130 <frame_dummy>:
1130: e9 7b ff ff ff jmp 10b0 <register_tm_clones>
0000000000001135 <before_main>:
1135: 55 push rbp
1136: 48 89 e5 mov rbp,rsp
1139: 48 8d 3d c4 0e 00 00 lea rdi,[rip+0xec4]
1140: e8 eb fe ff ff call 1030 <puts@plt>
1145: 90 nop
1146: 5d pop rbp
1147: c3 ret
0000000000001148 <before_main2>:
1148: 55 push rbp
1149: 48 89 e5 mov rbp,rsp
114c: 48 8d 3d be 0e 00 00 lea rdi,[rip+0xebe]
1153: e8 d8 fe ff ff call 1030 <puts@plt>
1158: 90 nop
1159: 5d pop rbp
115a: c3 ret
000000000000115b <after_main>:
115b: 55 push rbp
115c: 48 89 e5 mov rbp,rsp
115f: 48 8d 3d b9 0e 00 00 lea rdi,[rip+0xeb9]
1166: e8 c5 fe ff ff call 1030 <puts@plt>
116b: 90 nop
116c: 5d pop rbp
116d: c3 ret
000000000000116e <after_main2>:
116e: 55 push rbp
116f: 48 89 e5 mov rbp,rsp
1172: 48 8d 3d b3 0e 00 00 lea rdi,[rip+0xeb3]
1179: e8 b2 fe ff ff call 1030 <puts@plt>
117e: 90 nop
117f: 5d pop rbp
1180: c3 ret
$ ./a.out
This is init
This is init2
This is main
This is fini2
This is fini
As you see there is a snippet code from our binary that is the code of our functions.
When I ran the binary, the output was interesting. I never called afters and before functions anywhere in my main function, but when ran it, all of them executed before and after the main function.
Now I want to show you the magic. I use “readelf” to read the init_array and fini_array sections
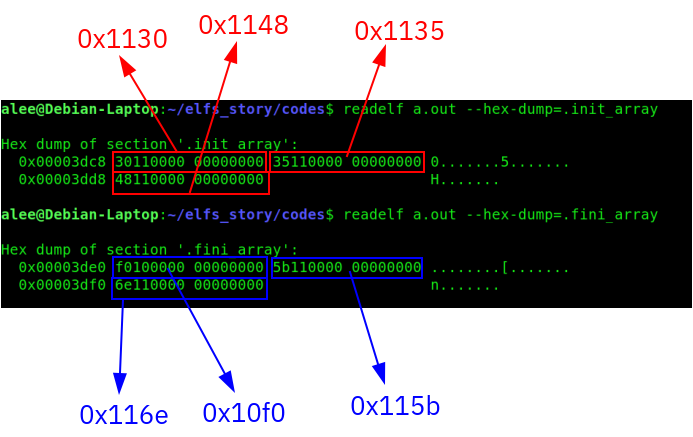
As you see I dump from the init/fini arrays by the readelf tool and now we see some addresses. in both sections, we have three 8 bytes of addresses. If you look at the addresses of “before_main”, and “before_main2” functions in the output of the “objdump”, the addresses of these two functions start from 0x1135 and 0x1148. These addresses also are in the init_array section. Also, we have another address, 0x1130 that is the address of the “frame_dummy” function that is nothing and is the default value that always is in the .init_array.
Also, we have the addresses of the “before_main” and “before_main2” functions in the .fini_array section.
So in this way, these functions get executed before/after any other codes.
But what about the .init/.fini sections? I should tell you that in newer versions of Linux, there are no codes in these two sections anymore. There are just some initialize/de-initialize codes that are created by compilers. Also, I tried and convert the codes in these sections to some NOP opcodes, and then ran the program. The result was awesome. The binary is executed normally without any problem.
But there is a big difference between the .init/.fini sections and .init_array/.fini_array.
The .init/.finit sections are sections by the type “PROGBITS” that show the contents of these sections are some codes that run at the runtime. But the type of the .init_array/.fini_array sections is “INIT/FINI_ARRAY” and there are no codes and are just some addresses of some functions that exist in the .text section. In this way, the contents of the .init/.fini arrays never execute at run time because those are some addresses.
But how do these addresses get executed in a binary file? I’ll talk about it in the next part.
1-3 .text ELF section
This is the main section of every ELF file. Because the main executable code of the binary file is stored in this section. When the compiler converts your high-level code to some machine codes, then writes them to this section. Sometimes this section also is called “.code”. the type of this section is “PROGBITS” and is an executable and allocatable section. So this section’s contents execute in the memory at the run time.
All functions and executables code are rested in this section. So this is the first location where tools like disassemblers meet.
The .text section is readable and executable and it is due to security reasons. If this section is writable, at the running time, the attacker can easily use a vulnerability and then write its shellcode to this section and then run it.
As said, the content of the .text section is a series of opcodes that run in the CPU. If you want to disassemble them, you can use the objdump tool.
$ objdump -d -M intel --section=.text a.out
a.out: file format elf64-x86-64
Disassembly of section .text:
0000000000001050 <_start>:
1050: 31 ed xor ebp,ebp
1052: 49 89 d1 mov r9,rdx
1055: 5e pop rsi
1056: 48 89 e2 mov rdx,rsp
1059: 48 83 e4 f0 and rsp,0xfffffffffffffff0
105d: 50 push rax
105e: 54 push rsp
105f: 4c 8d 05 9a 01 00 00 lea r8,[rip+0x19a] # 1200 <__libc_csu_fini>
1066: 48 8d 0d 33 01 00 00 lea rcx,[rip+0x133] # 11a0 <__libc_csu_init>
106d: 48 8d 3d 0d 01 00 00 lea rdi,[rip+0x10d] # 1181 <main>
1074: ff 15 66 2f 00 00 call QWORD PTR [rip+0x2f66] # 3fe0 <__libc_start_main@GLIBC_2.2.5>
107a: f4 hlt
107b: 0f 1f 44 00 00 nop DWORD PTR [rax+rax*1+0x0]this is a part of the whole .text section that is disassembled by objdump. The first function that you see is the “_start” function. This is the function that runs and calls the loader and then the loader calls the main function. I’ll talk about it in the next part.
1-4 .bss ELF section
When you writing code, you may define some variables. these variables are divided into some categories: global uninitialized variables, global initialized variables, local variables, and static variables.
Always in executable files, sections of the code and data are separated. This is because the data part of the binary file(for example variables), will charged at running time, but the code of the executable shouldn’t change. So the .text section is just readable and executable and the data part of the executable is writable and readable.
One of these sections that hold the variables for you is the “.bss” section. This section is designed for uninitialized variables.
The content of this section is nothing. This section hasn’t any content so the question is what is its usage when its content is NULL? The answer is simple: because it holds some null values :D.
OK imagine we have a code that has two uninitialized variables. One of them is a char(1-Byte) and another is an int(4-Byte).
The whole size of our uninitialized variables is 5-Byte. We know that they are uninitialized variables. So have not any values and we just need the size of them. This section just holds the size of all uninitialized variables in its section size.
Look at this code:
#include <stdio.h>
char* name; // uninitialized variable 8 bytes
char* family;// uninitialized variable 8 bytes
int main()
{
printf("name=%d family=%d ,sizeof(name),sizeof(family));
}
We have 2 uninitialized variables. Let’s compile it and see the content of the .bss section. I use readelf for this.
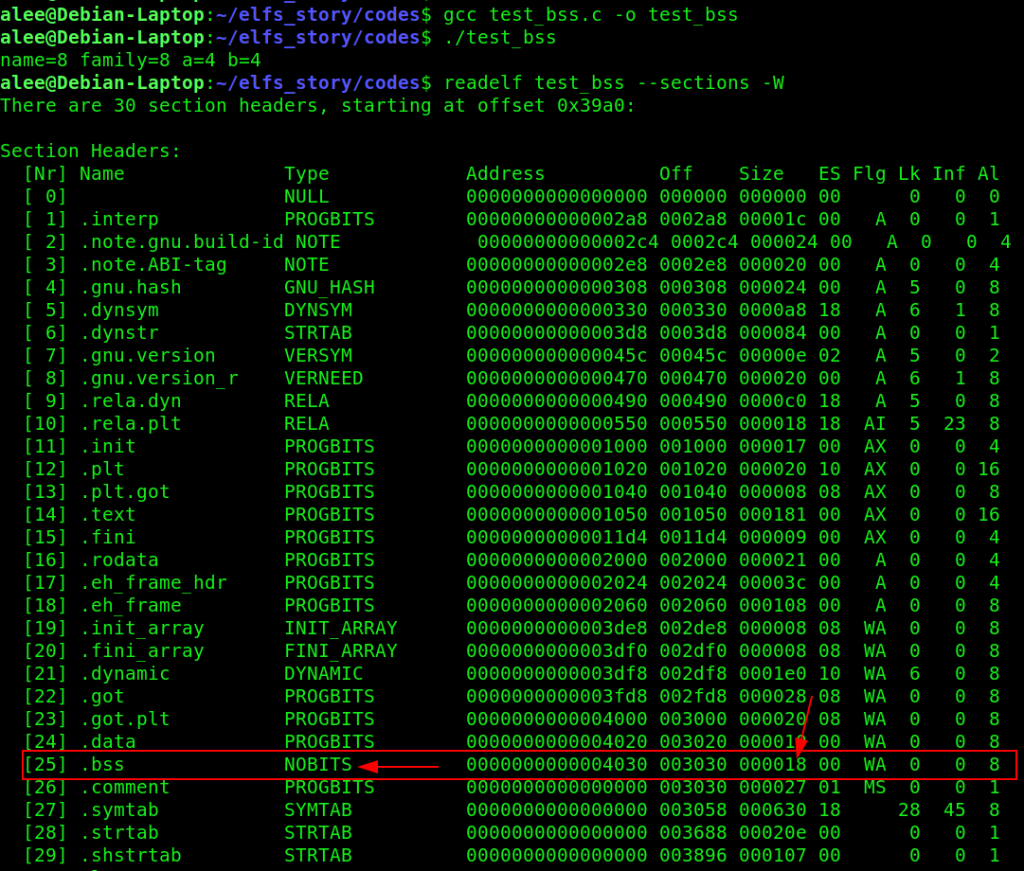
As you see the total size of our uninitialized variables is 8+8=16. In the .bss section size, we see the value is 0x18 or 24. So this value is equal to the size of our variables plus an additional 8 bytes. This is because always the default value of the .bss section is 8 bytes I included stdio.h and maybe in it there is an initialized value. I will test it for you in the .data section. Also, we see the type of this section is NOBITS and it means that we have a section within a program space with no data. If you look at its offset you see that its value is 0x3030 which is equal to the .comment section offset. This value is a dummy value for the .bss section because it hasn’t any content.
1-5 .rodata ELF section
We have another type of variable in programming, called them Read Only variables. These variables are those who are just for reading and not for changing. For example, if you declare a “const char”, this variable is a read-only one. Also when we use strings in some functions like print or scanf or other functions that have an argument with the “const char” type, they are put in this category.
This type of variable is stored in the “.rodata” section.
Let’s have an example:
#include <stdio.h>
const char* name="alee";
const int ca=0xaabbccdd;
int main()
{
printf("hello sizeof(name)=",sizeof(name));
}
In this sample code, we have two constant variables and a string in the print function. Let’s see the contents of the .rodata section by the readelf tool.
$ ./test_rodata
hello sizeof(name)=8
$ readelf --sections test_rodata -W
There are 30 section headers, starting at offset 0x39a8:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 00000000000002a8 0002a8 00001c 00 A 0 0 1
[ 2] .note.gnu.build-id NOTE 00000000000002c4 0002c4 000024 00 A 0 0 4
[ 3] .note.ABI-tag NOTE 00000000000002e8 0002e8 000020 00 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000000308 000308 000024 00 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000000330 000330 0000a8 18 A 6 1 8
[ 6] .dynstr STRTAB 00000000000003d8 0003d8 000084 00 A 0 0 1
[ 7] .gnu.version VERSYM 000000000000045c 00045c 00000e 02 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000000470 000470 000020 00 A 6 1 8
[ 9] .rela.dyn RELA 0000000000000490 000490 0000d8 18 A 5 0 8
[10] .rela.plt RELA 0000000000000568 000568 000018 18 AI 5 23 8
[11] .init PROGBITS 0000000000001000 001000 000017 00 AX 0 0 4
[12] .plt PROGBITS 0000000000001020 001020 000020 10 AX 0 0 16
[13] .plt.got PROGBITS 0000000000001040 001040 000008 08 AX 0 0 8
[14] .text PROGBITS 0000000000001050 001050 000171 00 AX 0 0 16
[15] .fini PROGBITS 00000000000011c4 0011c4 000009 00 AX 0 0 4
[16] .rodata PROGBITS 0000000000002000 002000 000027 00 A 0 0 4
[17] .eh_frame_hdr PROGBITS 0000000000002028 002028 00003c 00 A 0 0 4
[18] .eh_frame PROGBITS 0000000000002068 002068 000108 00 A 0 0 8
[19] .init_array INIT_ARRAY 0000000000003de8 002de8 000008 08 WA 0 0 8
[20] .fini_array FINI_ARRAY 0000000000003df0 002df0 000008 08 WA 0 0 8
[21] .dynamic DYNAMIC 0000000000003df8 002df8 0001e0 10 WA 6 0 8
[22] .got PROGBITS 0000000000003fd8 002fd8 000028 08 WA 0 0 8
[23] .got.plt PROGBITS 0000000000004000 003000 000020 08 WA 0 0 8
[24] .data PROGBITS 0000000000004020 003020 000018 00 WA 0 0 8
[25] .bss NOBITS 0000000000004038 003038 000008 00 WA 0 0 1
[26] .comment PROGBITS 0000000000000000 003038 000027 01 MS 0 0 1
[27] .symtab SYMTAB 0000000000000000 003060 000630 18 28 45 8
[28] .strtab STRTAB 0000000000000000 003690 00020d 00 0 0 1
[29] .shstrtab STRTAB 0000000000000000 00389d 000107 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
$ readelf --hex-dump=.rodata test_rodata
Hex dump of section '.rodata':
0x00002000 01000200 616c6565 00000000 ddccbbaa ....alee........
0x00002010 68656c6c 6f207369 7a656f66 286e616d hello sizeof(nam
0x00002020 65293d25 640a00 e)=%d..
The size of the .rodata is 0x27 or 39 bytes. The type of this section is A which means this is a loadable section in the execution time. Also, this section doesn’t have a write flag which means it is just readable content.
Also, you see the contents of the .rodata section. In this section, we have 4 values.
The first 4 red bytes probably are for the stdlib because we included “stdio.h”.
The next 8 yellow bytes are for the “name” variable which is the string “alee”. We know the size of a char* is 8 bytes in this program. (Look at the “sizeof” function output).
After that, we have 4 pink bytes which are for the “ca” integer.
At the end, the other bytes are the format string used in the print function, with a null(0x00) char at the end.
1-6 .data ELF section
I talked about uninitialized variables. but you may have other types of variables in your program like global initialized variables. This type of variable is kept in another section named .data. This is because their value may change during the execution and so they need a space to hold the new changes.
This section is a section with PROGBITS type so this section will load in the memory and contain program data. Let’s see a sample. In this code, I declared two variables: an integer and a const char*.
#include <stdio.h>
int num = 0xaabbccdd;
char* name="alee";
int a=0xff;
int main()
{
printf("num size=%d name size=%d\n",sizeof(num),sizeof(name));
}
Now we have three global initialized variables. I compile this code and dump the contents of the .data section.
$ ./test_data
num size=4 name size=4 a size=4
$ readelf --sections test_data -W
There are 30 section headers, starting at offset 0x39c8:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 00000000000002a8 0002a8 00001c 00 A 0 0 1
[ 2] .note.gnu.build-id NOTE 00000000000002c4 0002c4 000024 00 A 0 0 4
[ 3] .note.ABI-tag NOTE 00000000000002e8 0002e8 000020 00 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000000308 000308 000024 00 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000000330 000330 0000a8 18 A 6 1 8
[ 6] .dynstr STRTAB 00000000000003d8 0003d8 000084 00 A 0 0 1
[ 7] .gnu.version VERSYM 000000000000045c 00045c 00000e 02 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000000470 000470 000020 00 A 6 1 8
[ 9] .rela.dyn RELA 0000000000000490 000490 0000c0 18 A 5 0 8
[10] .rela.plt RELA 0000000000000550 000550 000018 18 AI 5 23 8
[11] .init PROGBITS 0000000000001000 001000 000017 00 AX 0 0 4
[12] .plt PROGBITS 0000000000001020 001020 000020 10 AX 0 0 16
[13] .plt.got PROGBITS 0000000000001040 001040 000008 08 AX 0 0 8
[14] .text PROGBITS 0000000000001050 001050 000171 00 AX 0 0 16
[15] .fini PROGBITS 00000000000011c4 0011c4 000009 00 AX 0 0 4
[16] .rodata PROGBITS 0000000000002000 002000 00002c 00 A 0 0 8
[17] .eh_frame_hdr PROGBITS 000000000000202c 00202c 00003c 00 A 0 0 4
[18] .eh_frame PROGBITS 0000000000002068 002068 000108 00 A 0 0 8
[19] .init_array INIT_ARRAY 0000000000003de8 002de8 000008 08 WA 0 0 8
[20] .fini_array FINI_ARRAY 0000000000003df0 002df0 000008 08 WA 0 0 8
[21] .dynamic DYNAMIC 0000000000003df8 002df8 0001e0 10 WA 6 0 8
[22] .got PROGBITS 0000000000003fd8 002fd8 000028 08 WA 0 0 8
[23] .got.plt PROGBITS 0000000000004000 003000 000020 08 WA 0 0 8
[24] .data PROGBITS 0000000000004020 003020 00001c 00 WA 0 0 8
[25] .bss NOBITS 000000000000403c 00303c 000004 00 WA 0 0 1
[26] .comment PROGBITS 0000000000000000 00303c 000027 01 MS 0 0 1
[27] .symtab SYMTAB 0000000000000000 003068 000648 18 28 45 8
[28] .strtab STRTAB 0000000000000000 0036b0 00020c 00 0 0 1
[29] .shstrtab STRTAB 0000000000000000 0038bc 000107 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
$ readelf --hex-dump=.data test_data
Hex dump of section '.data':
0x00004020 00000000 00000000 28400000 00000000 ........(@......
0x00004030 ddccbbaa 616c6565 ff000000 ....alee....
As you see the .data section size is 0x1c or 28 bytes and its alignment is 8. Also, our variables have 4+4+4=12 bytes. So there are 20 additional bytes. So what are these additional bytes? Let dump from the .data section
I think the 8 red bytes is a variable that is in the stdlib because I included “stdio.h”. I’ll test it for you.
Also, the 8 blue bytes are for stdlib. The 4 yellow byte value is our “num” variable and after that, we have 4 pink bytes that is our name array bytes. In the end, the white bytes are for our “a” variable.
All of the examples that I used in the .rodata,.bss, and .data sections had some additional bytes in the related section and I said that these bytes are related to stdlib because I included the stdio.h. But now I want to show you an example to understand better and prove it.
For this, I compile the code used in the .data section again and this time I tell the compiler not to link the stdlib to the final executable. For this, you should pass the “-nostdlib” flag to GCC. But you shouldn’t use any stdlib functions in your code. So you should remove the print function.
So our new code becomes this:
int num = 0xaabbccdd;
char* name="alee";
int a=0xff;
int main()
{
}I removed the print function, But all variables are the same as previous example. Let’s compile it:
$ gcc test_data.c -o test_data_nostd -nostdlib
Now I dump the contents of the .data section :
$ readelf --sections test_data_nostd -W
There are 15 section headers, starting at offset 0x3350:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 00000000000002a8 0002a8 00001c 00 A 0 0 1
[ 2] .note.gnu.build-id NOTE 00000000000002c4 0002c4 000024 00 A 0 0 4
[ 3] .gnu.hash GNU_HASH 00000000000002e8 0002e8 00001c 00 A 4 0 8
[ 4] .dynsym DYNSYM 0000000000000308 000308 000018 18 A 5 1 8
[ 5] .dynstr STRTAB 0000000000000320 000320 000001 00 A 0 0 1
[ 6] .text PROGBITS 0000000000001000 001000 00000b 00 AX 0 0 1
[ 7] .eh_frame_hdr PROGBITS 0000000000002000 002000 000014 00 A 0 0 4
[ 8] .eh_frame PROGBITS 0000000000002018 002018 000038 00 A 0 0 8
[ 9] .dynamic DYNAMIC 0000000000003f30 002f30 0000d0 10 WA 5 0 8
[10] .data PROGBITS 0000000000004000 003000 00000c 00 WA 0 0 4
[11] .comment PROGBITS 0000000000000000 00300c 000027 01 MS 0 0 1
[12] .symtab SYMTAB 0000000000000000 003038 000240 18 13 16 8
[13] .strtab STRTAB 0000000000000000 003278 00004f 00 0 0 1
[14] .shstrtab STRTAB 0000000000000000 0032c7 000086 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
$ readelf --hex-dump=.data test_data_nostd
Hex dump of section '.data':
0x00004000 ddccbbaa 616c6565 ff000000 ....alee....
As you see the size of the .data section becomes 0xc or 12 bytes which equals the size of our variables:4+8+4=12 bytes. Also, the contents of the .data section are just three values that we have in our code. two integers and one string.
So we found out that the contents of sections of the ELF file don’t depend just on our code. Always other things in linking time and also in compile time, mixed in our binary.
1-7 .comment ELF section
This section contains the information of the compiler and OS and their version which was used to compile the executable file. The flags for this section are M (merge) and S (strings). which indicates that the section contains some strings also this section may be merged by loading the file into the memory with other sections. This means that this section might rest in the part of the memory that other sections are loaded.
$ readelf --hex-dump=.comment test_data
Hex dump of section '.comment':
0x00000000 4743433a 20284465 6269616e 2031302e GCC: (Debian 10.
0x00000010 322e312d 36292031 302e322e 31203230 2.1-6) 10.2.1 20
0x00000020 32313031 313000 210110.
As you see the content of this section is the name of the compiler and the version of the OS.
Now I want to talk about some special sections that are related to each other.
1-8 .symtab and .dynsym ELF sections
This section is a table that contains symbol information. As said, a symbol is a variable or a function in an ELF file.
Unlike previous sections that talked about them, this section has a special structure that is used to hold the information of the symbols.
The .symtab(SHT_SYMTAB) table contains every symbol that describes the associated ELF file. This symbol table is typically non-allocable, so not load in the memory of the process at running time.
On the other hand, we have a .dynsym(SHT_DYNSYM) table that contains a subset of the symbols from the .symtab table that are needed to support dynamic linking. This symbol table is allocable, so loads in the memory of the process at running time.
$ readelf ./test_symtab --sections -W
There are 15 section headers, starting at offset 0x3268:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 00000000000002a8 0002a8 00001c 00 A 0 0 1
[ 2] .note.gnu.build-id NOTE 00000000000002c4 0002c4 000024 00 A 0 0 4
[ 3] .gnu.hash GNU_HASH 00000000000002e8 0002e8 00001c 00 A 4 0 8
[ 4] .dynsym DYNSYM 0000000000000308 000308 000018 18 A 5 1 8
[ 5] .dynstr STRTAB 0000000000000320 000320 000001 00 A 0 0 1
[ 6] .text PROGBITS 0000000000001000 001000 000035 00 AX 0 0 1
[ 7] .eh_frame_hdr PROGBITS 0000000000002000 002000 00001c 00 A 0 0 4
[ 8] .eh_frame PROGBITS 0000000000002020 002020 000058 00 A 0 0 8
[ 9] .dynamic DYNAMIC 0000000000003f30 002f30 0000d0 10 WA 5 0 8
[10] .data PROGBITS 0000000000004000 003000 00000c 00 WA 0 0 4
[11] .comment PROGBITS 0000000000000000 00300c 00001f 01 MS 0 0 1
[12] .symtab SYMTAB 0000000000000000 003030 000150 18 13 6 8
[13] .strtab STRTAB 0000000000000000 003180 000060 00 0 0 1
[14] .shstrtab STRTAB 0000000000000000 0031e0 000086 00 0 0 1
As you see the symtab and dynsym sections are of SYMTAB, and DYNSYM types and the .symtab hasn’t any address and flags value. This is because this section never loads in the memory at the run time. The information that is stored in this section is just useable for debugging purposes due to it, this information isn’t needed at run time so the loader never loads this section to the memory.
On the other hand, you see the .dynsym has these values so it should load at the memory in running time.
These sections contain a table based on the “ELF64_Sym” structure which exists in the “/usr/include/elf.h” file (All structures and data used for programming and working with the elf format are in this header file).
typedef struct
{
Elf64_Word st_name; (4-Byte) /* Symbol name (string tbl index) */
unsigned char st_info; (1-Byte) /* Symbol type and binding */
unsigned char st_other; (1-Byte) /* Symbol visibility */
Elf64_Section st_shndx; (2-Byte) /* Section index */
Elf64_Addr st_value; (8-Byte) /* Symbol value */
Elf64_Xword st_size; (8-Byte) /* Symbol size */
} Elf64_Sym;
As you see the size of a symbol equals to 24-Bytes.
st_name: is a value that points to an index of the string table section that is the start of a null-terminated string which is the name of the symbol.
The .strtab section serves as the reference string table for .symtab, while the .dynstr section serves as the reference string table for the .dynsym section.
st_info: The next 1 byte is a combination of symbol type and its binding type. The 4 high significant bits are binding type and the 4 low significant bits are a type of symbol.
| Type Name | Value |
|---|---|
STT_NOTYPE | 0 |
STT_OBJECT (variable, an array, and so on.) | 1 |
STT_FUNC (function in the object file) | 2 |
STT_SECTION (ponts to a section of ELF file) | 3 |
STT_FILE (name of the source file associated with the object file) | 4 |
STT_COMMON | 5 |
STT_TLS | 6 |
STT_LOOS (reserved for operating system) | 10 |
STT_HIOS (reserved for operating system) | 12 |
STT_LOPROC (reserved for processor-specific) | 13 |
STT_HIPROC (reserved for processor-specific) | 15 |
| Type Name | Value |
|---|---|
STB_LOCAL | 0 |
STB_GLOBAL | 1 |
STB_WEAK | 2 |
STB_LOOS | 10 |
STB_HIOS | 12 |
STB_LOPROC | 13 |
STB_HIPROC | 15 |
This information is very important at linking time where the linker wants to link objects files together. It should know about how to bind symbols.
STB_LOCAL: Local symbols are not visible outside the object file containing their definition. Local symbols of the same name may exist in multiple files without interfering with each other. For example when you define a static global variable or function in one of your .c/cpp files. in this way, you can define variables and functions by the same name in other files.
STB_GLOBAL: Global symbols are visible to all object files being combined. One file’s definition of a global symbol will satisfy another file’s undefined reference to the same global symbol. Like when you define a global variable or a function. in this way, you can’t have another global variable or function with the same name in other .c/cpp files.
STB_WEAK: Weak symbols resemble global symbols, but their definitions have lower precedence. for example, if you have a weak variable or function in one of your .c/cpp files, and on the other hand you have another variable or function by the same name in another file but with type global, at the linking time, the linker replaces the weak symbol with the second symbol. This is useful when someone wants to let the developer use its own variable or function at the link time. you can define a weak symbol with “__attribute__((weak))” atrribute in your code when using gcc.
Other types are reserved for operating system-specific and processor-specific semantics.
In each symbol table, all symbols with STB_LOCAL binding precede the weak and global symbols.
Also, the value of the section_info of the symbol table section is the first non-LOCAL type symbol index, which in our case is 6.
Then the next 1 byte is the visibility of a symbol. This value is important for static and dynamic linkers to find out which symbol should be visible to other objects and which one is not. Using these attributes, we can flag extra information for the dynamic loader so it can know which symbols are for public consumption, and which are for internal use only.
| Visibility Name | Value |
|---|---|
STV_DEFAULT | 0 |
STV_INTERNAL | 1 |
STV_HIDDEN | 2 |
STV_PROTECTED | 3 |
STV_DEFAULT: The visibility of symbols with the STV_DEFAULT attribute is as specified by the symbol’s binding type. That is, global and weak symbols are visible outside of their defining component (executable file or shared object). Local symbols are hidden
STV_HIDDEN: A symbol defined in the current component is hidden if its name is not visible to other components.
I will talk about the linking process in the next part.
For now, let’s see an example:
#include <stdio.h>
int g_var=0xaa;
static int s_var=0xbb;
__attribute__((weak)) int w_var=0xcc;
int func1()
{
return 1000;
}
int main()
{
int var1=2;
char var2=1;
return func1()+ var1+var2;
}
I compiled this code and now I want to show you the symbol table of this file.
$ readelf --symbols ./test_symtab
Symbol table '.dynsym' contains 1 entry:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterTMCloneTable
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.2.5 (2)
3: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
Symbol table '.symtab' contains 14 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 FILE LOCAL DEFAULT ABS test_symtab.c
2: 0000000000004004 4 OBJECT LOCAL DEFAULT 10 s_var
3: 0000000000000000 0 FILE LOCAL DEFAULT ABS
4: 0000000000003f30 0 OBJECT LOCAL DEFAULT 9 _DYNAMIC
5: 0000000000002000 0 NOTYPE LOCAL DEFAULT 7 __GNU_EH_FRAME_HDR
6: 0000000000004000 4 OBJECT GLOBAL DEFAULT 10 g_var
7: 0000000000004008 4 OBJECT WEAK DEFAULT 10 w_var
8: 0000000000001000 11 FUNC GLOBAL DEFAULT 6 func1
9: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND _start
10: 000000000000400c 0 NOTYPE GLOBAL DEFAULT 10 __bss_start
11: 000000000000100b 42 FUNC GLOBAL DEFAULT 6 main
12: 000000000000400c 0 NOTYPE GLOBAL DEFAULT 10 _edata
13: 0000000000004010 0 NOTYPE GLOBAL DEFAULT 10 _end
The first symbol in both sections always is a NULL symbol that hasn’t any value.
As you see the g_var is defined as a global variable in the code and in the symbols you see its binding type is GLOBAL and its type is OBJECT also its Section_Index is 10 which in our case is the index of the .data section which means this symbol is used in there and its address is 0x4000. In this way, if we have another global variable with this name in another object file, the linker gives us an error for duplicate definitions.
Also for s_var, its binding type is LOCAL because we defined it as a static variable that is valid just in its object file and in this way, if we have another global variable with this name in another object file, the linker is OK.
Another variable is w_var which is a weak variable. You see its binding type is WEAK. In this way, if we have another symbol with the same name in another file, the linker doesn’t show us an error and also uses it for this name.
The symbols in the .dynsym section have the same structure but all symbols in the dynsym section have a value of NULL and size 0. This is because they are unknown to the linker at compile time.
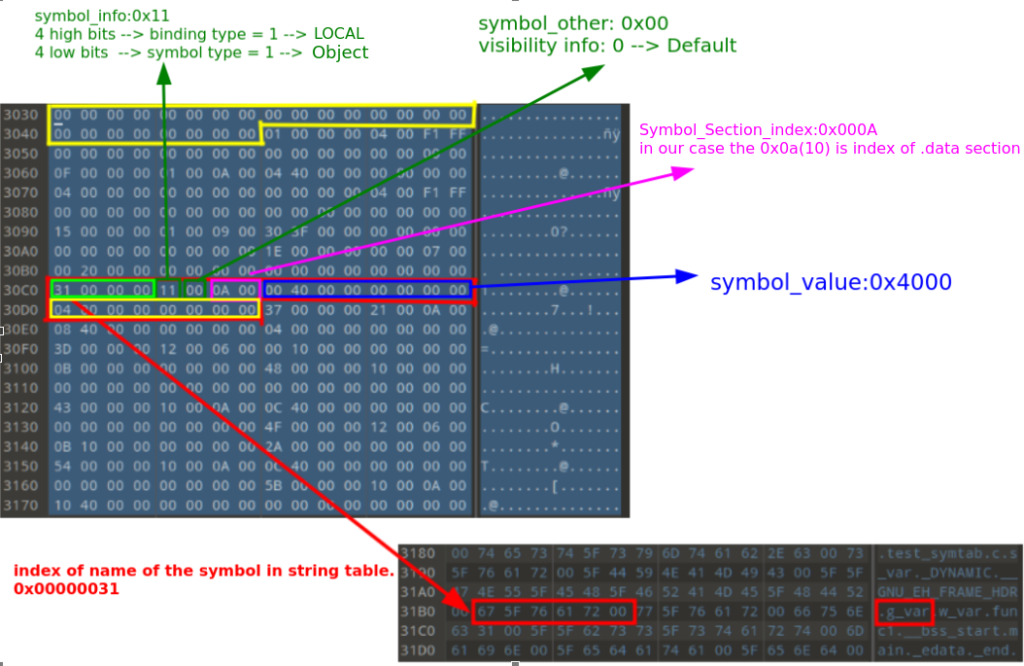
As you see in the above figure, the first symbol is a NULL symbol. also, you see the size of a symbol structure is 24 bytes.
Tip: When a symbol’s type is SECTION, it means the symbol is pointing to a Section of the ELF file. So the value of Symbol_Section is the index number of the Section, and the Symbol_Value is the offset in the file where the Section content rests.
For these types of symbols, the Symbol_Name value is NULL because the section names are stored in the .shstrtab section.
You see a sample of these symbols in below.
Symbol table '.symtab' contains 65 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 00000000000002a8 0 SECTION LOCAL DEFAULT 1 .interp
2: 00000000000002c4 0 SECTION LOCAL DEFAULT 2 .note.gnu.build-id
3: 00000000000002e8 0 SECTION LOCAL DEFAULT 3 .note.ABI-tag
4: 0000000000000308 0 SECTION LOCAL DEFAULT 4 .gnu.hash
5: 0000000000000330 0 SECTION LOCAL DEFAULT 5 .dynsym
6: 00000000000003c0 0 SECTION LOCAL DEFAULT 6 .dynstr
7: 000000000000043e 0 SECTION LOCAL DEFAULT 7 .gnu.version
8: 0000000000000450 0 SECTION LOCAL DEFAULT 8 .gnu.version_r
9: 0000000000000470 0 SECTION LOCAL DEFAULT 9 .rela.dyn
10: 0000000000001000 0 SECTION LOCAL DEFAULT 10 .init
11: 0000000000001020 0 SECTION LOCAL DEFAULT 11 .plt
12: 0000000000001030 0 SECTION LOCAL DEFAULT 12 .plt.got
13: 0000000000001040 0 SECTION LOCAL DEFAULT 13 .text
14: 0000000000001194 0 SECTION LOCAL DEFAULT 14 .fini
1-9 .strtab .dynstr .shstrtab ELF sections
We worked many times in this part with this section. The string table section is a source for other sections that contain string values. All symbols’ names are stored in .dynstr and .strtab sections as some null-terminated strings that start with a NULL byte at the beginning. We have worked with this particular section on numerous occasions.
The string table section acts as a reference for other sections that hold string values. The names of all symbols are stored in the .dynstr and .strtab sections as null-terminated strings that begin with a NULL byte at the start.
There is a key difference between the .strtab and .dynstr sections. The .strtab, which contains symbol names, does not load in memory at runtime. However, the .dynstr, which contains dynamic symbol names, does.
There is another section, called the .shstrtab section, that stores the names of sections. All of these sections are of type STRTAB.
You see an example of the string table structure in the ELF file. All string tables have the same structure. Some null-terminated strings.
Also, the Address value of .shstrtab and .strtab is NULL. This is because these two string tables don’t load at the memory in running time.
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 6] .dynstr STRTAB 00000000000003c0 0003c0 00007d 00 A 0 0 1
.
.
.
[27] .strtab STRTAB 0000000000000000 003678 0001f9 00 0 0 1
[28] .shstrtab STRTAB 0000000000000000 003871 0000fd 00 0 0 1
1-10 .rle* and .rela* ELF Sections
Every section that you see in the ELF file that starts with RELA is a relocation table.
But the postfix of the name specifies when the relocation should happen.
I talked about relocation in the previous part of this story. Relocation is a series of changes at the code level that causes the binary file to find out its external symbol addresses.
The relocation process is divided into two phases. The first phase takes place during the linking phase at compile time, while the second phase occurs when the executable runs and is loaded by the dynamic loader. Each phase has a specific RELA section. For instance, during the linking phase of the compilation process, there is a section in the object file named “.rela.text”.
Also, we have rela.dyn and rela.plt for dynamic linker at the running time.
All of these sections follow the same structure, which includes information about relocations. which contains some information about relocations.
For example, you can see two types of relocation tables section:
$ readelf --sections ./test_data.obj -W
There are 13 section headers, starting at offset 0x2b0:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 0000000000000000 000040 00002e 00 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 000200 000030 18 I 10 1 8
[ 3] .data PROGBITS 0000000000000000 000070 00000c 00 WA 0 0 4
[ 4] .bss NOBITS 0000000000000000 00007c 000000 00 WA 0 0 1
[ 5] .rodata PROGBITS 0000000000000000 000080 000024 00 A 0 0 8
[ 6] .comment PROGBITS 0000000000000000 0000a4 000020 01 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 0000000000000000 0000c4 000000 00 0 0 1
[ 8] .eh_frame PROGBITS 0000000000000000 0000c8 000038 00 A 0 0 8
[ 9] .rela.eh_frame RELA 0000000000000000 000230 000018 18 I 10 8 8
[10] .symtab SYMTAB 0000000000000000 000100 0000d8 18 11 4 8
[11] .strtab STRTAB 0000000000000000 0001d8 000024 00 0 0 1
[12] .shstrtab STRTAB 0000000000000000 000248 000061 00 0 0 1
This is a section list of an object file(an executable file before linking). As you can see there are two relocation tables in the sections that are needed by the static linker.
$ readelf --sections ./test_data.elf -W
There are 31 section headers, starting at offset 0x36f8:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 0000000000000318 000318 00001c 00 A 0 0 1
[ 2] .note.gnu.property NOTE 0000000000000338 000338 000020 00 A 0 0 8
[ 3] .note.gnu.build-id NOTE 0000000000000358 000358 000024 00 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000037c 00037c 000020 00 A 0 0 4
[ 5] .gnu.hash GNU_HASH 00000000000003a0 0003a0 000024 00 A 6 0 8
[ 6] .dynsym DYNSYM 00000000000003c8 0003c8 0000a8 18 A 7 1 8
[ 7] .dynstr STRTAB 0000000000000470 000470 00008f 00 A 0 0 1
[ 8] .gnu.version VERSYM 0000000000000500 000500 00000e 02 A 6 0 2
[ 9] .gnu.version_r VERNEED 0000000000000510 000510 000030 00 A 7 1 8
[10] .rela.dyn RELA 0000000000000540 000540 0000c0 18 A 6 0 8
[11] .rela.plt RELA 0000000000000600 000600 000018 18 AI 6 24 8
[12] .init PROGBITS 0000000000001000 001000 000017 00 AX 0 0 4
[13] .plt PROGBITS 0000000000001020 001020 000020 10 AX 0 0 16
[14] .plt.got PROGBITS 0000000000001040 001040 000008 08 AX 0 0 8
[15] .text PROGBITS 0000000000001050 001050 000117 00 AX 0 0 16
[16] .fini PROGBITS 0000000000001168 001168 000009 00 AX 0 0 4
[17] .rodata PROGBITS 0000000000002000 002000 00002c 00 A 0 0 8
[18] .eh_frame_hdr PROGBITS 000000000000202c 00202c 00002c 00 A 0 0 4
[19] .eh_frame PROGBITS 0000000000002058 002058 0000ac 00 A 0 0 8
[20] .init_array INIT_ARRAY 0000000000003dd0 002dd0 000008 08 WA 0 0 8
[21] .fini_array FINI_ARRAY 0000000000003dd8 002dd8 000008 08 WA 0 0 8
[22] .dynamic DYNAMIC 0000000000003de0 002de0 0001e0 10 WA 7 0 8
[23] .got PROGBITS 0000000000003fc0 002fc0 000028 08 WA 0 0 8
[24] .got.plt PROGBITS 0000000000003fe8 002fe8 000020 08 WA 0 0 8
[25] .data PROGBITS 0000000000004008 003008 00001c 00 WA 0 0 8
[26] .bss NOBITS 0000000000004024 003024 000004 00 WA 0 0 1
[27] .comment PROGBITS 0000000000000000 003024 00001f 01 MS 0 0 1
[28] .symtab SYMTAB 0000000000000000 003048 0003a8 18 29 18 8
[29] .strtab STRTAB 0000000000000000 0033f0 0001ea 00 0 0 1
[30] .shstrtab STRTAB 0000000000000000 0035da 00011a 00 0 0 1
Here is a list of the sections of an executable file after linking. As you can see, there are two relocation tables in the sections which are necessary for the dynamic linker to function properly. Additionally, you will notice that there are no longer .rela.text and .rela.eh_frame sections since they are only needed during linking and are subsequently deleted by the linker.
In the following section of this story, I will discuss linking and provide further details on the relocation process.
1-11 .gnu.version and .gnu.version_r ELF sections
Before I start talking about these two sections, first I should talk about an important topic in the Linux ELF files, symbol versioning.
Symbol versioning is a feature of ELF files that makes it possible for you can run an ELF on other and also older distro (Backward compatibility).
For example, you have a program that runs in a Linux OS with kernel version 3.0 which has an X version of the libstd library. Now you want to run it on an OS that has an older version of libstd. In this way, you can compile your ELF file of the program with multiple libstd versions to support backward compatibility.
So long story short, symbol versioning allows to addition of version information to symbols. This can be used to express symbol version requirements or to provide certain symbols multiple times in the same ELF file with different versions.
Symbol Versioning is implemented by 3 section types: SHT_GNU_VERSYM, SHT_GNU_VERDEF, and SHT_GNU_VERNEED. So these sections are .gnu.version and .gnu.version_r.
OK Let’s have an example for this:
#include <stdio.h>
#include <stdlib.h>
int main()
{
int input=0;
scanf("%d",&input);
printf("intput is %d\n",input);
exit(0);
}
In this code, I used two functions, scanf, and printf from the std library and compiled it with gcc. Now take a look at its dynamic symbols. Because these functions are external functions and the linker should resolve them in the run time.
$ readelf --dyn-syms ./main.o
Symbol table '.dynsym' contains 9 entries:
Num: Value Size Type Bind Vis Ndx Name
0: 0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_deregisterTMCloneTab
2: 0000000000000000 0 FUNC GLOBAL DEFAULT UND printf@GLIBC_2.2.5 (2)
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.2.5 (2)
4: 0000000000000000 0 NOTYPE WEAK DEFAULT UND __gmon_start__
5: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __isoc99_scanf@GLIBC_2.7 (3)
6: 0000000000000000 0 FUNC GLOBAL DEFAULT UND exit@GLIBC_2.2.5 (2)
7: 0000000000000000 0 NOTYPE WEAK DEFAULT UND _ITM_registerTMCloneTable
8: 0000000000000000 0 FUNC WEAK DEFAULT UND __cxa_finalize@GLIBC_2.2.5 (2)
As you can see, the output of the readelf for dynamic symbols has some @ characters followed by a GLIBC and a series number. But if you look at the .dynsym section and .dynstr table, you see just the names of these functions without the @GLIBC_X.X.X string. So how readelf appends these strings at the end of the names of symbols?
The answer is here: These GLIBC versions come from the .gnu.version and .gnu.version_r sections.
.gnu.version which has a section type of SHT_GNU_VERSYM, should, contain the Symbol Version Table. This section also should have the same number of entries as the Dynamic Symbol Table in the .dynsym section. So if an ELF file has 10 dynamic symbols in its .,dynsym table, the .gnu.version section should have 10 entries.
The structure of this section is an array of series 2-byte values which indicates the indicator of the symbol. This value just specifies the version number and not its name.
$readelf --hex-dump=.gnu.version ./main.o
Hex dump of section '.gnu.version':
0000 0000 0200 0200 0000 0300 0200 0000 ................
0200 ..
As you can see in the hex-dump of the .gnu.version section where I separated them into 2-byte groups, there are some numbers in little-endian format.
Every 2-byte value is the version number for a symbol in the .dynsym section. For example, the third value is 0x0002 which indicates the version of the third symbol in the .dynsym, which is printf. If you look at the result of the readelf output from the .dynsym section, you see at the end of the third line, value 2.
Also, the sixth 2-byte value in the .gnu.version section is 0x0003 which indicates the version of the scanf function, which is 3.
There are 9 symbols in the .dynsym section, and we should have 9 values also in the .gnu.version (9*2 bytes = 18 bytes is the size of the .gnu.version section).
$ readelf --version-info ./main.o
Version symbols section '.gnu.version' contains 9 entries:
Addr: 0x0000000000000542 Offset: 0x000542 Link: 6 (.dynsym)
000: 0 (*local*) 0 (*local*) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5)
004: 0 (*local*) 3 (GLIBC_2.7) 2 (GLIBC_2.2.5) 0 (*local*)
008: 2 (GLIBC_2.2.5)
Version needs section '.gnu.version_r' contains 1 entry:
Addr: 0x0000000000000558 Offset: 0x000558 Link: 7 (.dynstr)
000000: Version: 1 File: libc.so.6 Cnt: 2
0x0010: Name: GLIBC_2.7 Flags: none Version: 3
0x0020: Name: GLIBC_2.2.5 Flags: none Version: 2
The .gnu.version_r holds the information about symbols versions such as mapping a version integer to its string name of that library.
The command mentioned above displays the value of the .gnu.version section. This helps us to identify the versions of symbols present in this section.
However, we may wonder about the meaning of the GLIBC_X.X.X strings that appear in the output of the readelf command. The answer lies in the .gnu.version_r section, which contains information mapping a version integer to its corresponding string name of that library.
The .gnu.version_r holds the information about symbols versions such as mapping a version integer to its string name of that library.
The command mentioned above displays the value of the .gnu.version section. This helps us to identify the versions of symbols present in this section.
However, we may wonder about the meaning of the GLIBC_X.X.X strings that appear in the output of the readelf command. The answer lies in the .gnu.version_r section, which contains information mapping a version integer to its corresponding string name of that library.
typedef struct
{
Elf64_Half vn_version; (2-Byte)
Elf64_Half vn_cnt; (2-Byte)
Elf64_Word vn_file; (4-Byte)
Elf64_Word vn_aux; (4-Byte)
Elf64_Word vn_next; (4-Byte)
} Elf64_Verneed;
typedef struct {
Elf64_Word vna_hash; (4-Byte)
Elf64_Half vna_flags; (2-Byte)
Elf64_Half vna_other; (2-Byte)
Elf64_Word vna_name; (4-Byte)
Elf64_Word vna_next; (4-Byte)
} Elf64_Vernaux;The “.gnu.version_r” section in Linux contains information about symbols and their dependence on library names and versions. This section has a unique structure known as ELFxx_Verneed, which has a size of 16 bytes in x86_64 architecture.
- “vn_version” is the version value of the structure, which is currently set to 1 and will be 0 if the versioning implementation is incompatibly altered.
- “vn_cnt” is the count of references to this library.
- “vn_file” is an offset in the “.symstr” section that represents the library filename.
- “vn_aux” is an offset to a corresponding entry in the Vernaux array, in bytes.
- “vn_next” is the offset to the next “verneed” entry, in bytes.
The section also has another structure known as Elf64_Vernaux, which describes the versions of the library needed in the binary file.
To help clarify this concept, let’s take an example. Suppose we want to see the version information of the “uptime” binary file, which is a command in Linux. We can use the “readelf” command to display this information.
Version information of the “uptime” binary file which is a command in the linux.
$ readelf --version-info --dyn-syms /bin/uptime -W
Symbol table '.dynsym' contains 36 entries:
Num: Value Size Type Bind Vis Ndx Name
0:0000000000000000 0 NOTYPE LOCAL DEFAULT UND
1:0000000000000000 0 FUNC GLOBAL DEFAULT UND procps_uptime_sprint@LIBPROC_2 (3)
2:0000000000000000 0 FUNC GLOBAL DEFAULT UND localtime@GLIBC_2.2.5 (2)
3:0000000000000000 0 FUNC GLOBAL DEFAULT UND __libc_start_main@GLIBC_2.34 (4)
4:0000000000000000 0 FUNC GLOBAL DEFAULT UND __errno_location@GLIBC_2.2.5 (2)
.
.
.
20: 0000000000000000 0 FUNC GLOBAL DEFAULT UND __printf_chk@GLIBC_2.3.4 (6)
21: 0000000000000000 0 FUNC GLOBAL DEFAULT UND procps_uptime@LIBPROC_2 (3)
Version symbols section '.gnu.version' contains 36 entries:
Addr: 0x0000000000000958 Offset: 0x00000958 Link: 6 (.dynsym)
000: 0 (*local*) 3 (LIBPROC_2) 2 (GLIBC_2.2.5) 4 (GLIBC_2.34)
004: 2 (GLIBC_2.2.5) 1 (*global*) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5)
008: 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5)
00c: 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 5 (GLIBC_2.4) 2 (GLIBC_2.2.5)
010: 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 1 (*global*) 2 (GLIBC_2.2.5)
014: 6 (GLIBC_2.3.4) 3 (LIBPROC_2) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5)
018: 3 (LIBPROC_2) 2 (GLIBC_2.2.5) 6 (GLIBC_2.3.4) 1 (*global*)
01c: 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5)
020: 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5) 2 (GLIBC_2.2.5)
Version needs section '.gnu.version_r' contains 2 entries:
Addr: 0x00000000000009a0 Offset: 0x000009a0 Link: 7 (.dynstr)
000000: Version: 1 File: libproc2.so.0 Cnt: 1
0x0010: Name: LIBPROC_2 Flags: none Version: 3
0x0020: Version: 1 File: libc.so.6 Cnt: 4
0x0030: Name: GLIBC_2.3.4 Flags: none Version: 6
0x0040: Name: GLIBC_2.4 Flags: none Version: 5
0x0050: Name: GLIBC_2.34 Flags: none Version: 4
0x0060: Name: GLIBC_2.2.5 Flags: none Version: 2
In the output, two file names appear in the .gnu.version_r section. One of them is libproc2.so, which has only one counter version reference. The other library is libc.so.6, which has four references listed. This output indicates that the uptime binary file uses some functions of libproc2.so version 3, named LIBPROC_2. It also uses libc.so.2 library versions 6, 5, 4, and 2, named GLIBC_2.3.4, GLIBC_2.4, GLIBC_2.34, and GLIBC_2.2.5, respectively.
For example, consider the “procps_uptime_sprint” function in the dynamic symbol table (dynsym). Its index in the dynsym section is 1, so we can find its version in the .gnu.version section at index 1, which is 3. To find out the version number 3 is related to which version, we can look at the .gnu.version_r section, which tells us that this version is related to LIBPROC_2.
Similarly, for the function “__printf_chk,” which has an index of 20 in the .dynsym section, we see that its version is 6. This version is in the reference section related to the GLIBC_2.3.4 version of the libc.so.6 library.

First line(Reds)
As before said the size of the Verneed structure is 16 bytes in 64 bits.
The Verneed structure starts with the version number which is currently set to 1. The next two bytes indicate the number of references to this library structure, which is set to 0x0001, indicating that there is only one entry of the Vernaux structure for this library.
The next four bytes indicate the index of the filename of this library in the .dynstr section. You can find the name of the library at the 0x01C0 index in the .dynstr section. In this case, the library name is “libproc2.so.0”, which means that this entry in the Verneed structure pertains to this specific library.
The next four bytes indicate the number of bytes between the start of the current Verneed structure and the start of the Vernaux structure for the current library. In our case, the value is 0x00000010(16). This means that the first entry of the Vernaux structure for the libproc2.so.0 library can be found by counting 16 bytes from the start of the current structure (09A0).
Finally, the last four bytes indicate the location of the next entry in the Verneed structure, which pertains to the next library. In our case, the value is 0x00000020(32). This means that the next entry can be found by counting 32 bytes from the beginning of the current Verneed structure, which pertains to the next library (the green line).
Second line(Yellows):
After each entry of the Verneed structure, there are one or more entries of the Vernaux structure, based on the counter value of the Verneed structure. In this particular case, after the first Verneed structure that is related to the libproc2.so.0, we have only one entry of the Vernaux.
The first four bytes of the Vernaux structure represent a hash value that the compiler calculated and placed there.
The following two bytes are for some flags which, in this case, are set to zero.
The next two bytes indicate the version value number, and it’s in sync with the numbers used in the .gnu.version section. In this case, the value is 0x0003.
The next four bytes indicate the index of the version string of this entry in the .dynstr section. You can find the string of the version at index 0x000001D8 in the .dynstr section. In this case, the library name is “LIBPROC_2”.
Finally, the last four bytes indicate the location of the next entry in the Vernaux structure, which pertains to the next version string. In our case, the value is 0x00000000. This means that there is no other entry for this library. As mentioned before, the counter of the versions for this library was 1, so there is no other entry.
Third line(Greens):
Now we have another entry of the Verneed structure.
This is because, at the first one, we saw that the vn_next value is 0x20. So after 32 bytes, we get here.
Now we have another library entry. But this time this one has 0x0004 counter value which indicates has 4 entries of Vernaux structure in continue.
Also, its index at the .dynstr is libc.so.6, and after that in the vn_aux, we see that the first entry is in 0x10 bytes after the beginning of this structure.
The last 4 bytes are 0x0, so there isn’t any other Verneed structure entry.
We can find out that this binary uses libc and libproc2.
Fourth line(Pinks):
The fourth line in the output, labeled “Pinks,” is another Vernaux structure that shows a version of the libc.so library.
The first value is a hash, followed by two bytes indicating flags that are usually set to zero in default mode.
The next two bytes show the number of the version value associated with this version (0x0006), which is the same value in the “.gnu.version”. Furthermore, the index in the “.dynstr” indicates that the string version is “GLIBC_2.3.4”.
Finally, the last four bytes indicate that the next Vernaux entry is located 0x10 bytes after the beginning of the current structure.
Although there are other entries, I have skipped them, but you can see the remaining three entries that indicate other versions of the libc.so library.
We can determine how the readelf identifies the versions of dynamic symbols. In our specific case, for each symbol in the dynamic symbols present in the .dynsym section, readelf searches for the matching index in the .gnu.version section to identify the corresponding version number. It then looks for this version number in the .gnu.version_r section to find the related version string in the .dynstr section.
But there is another tip. How we can find out that the version strings rest in the .dynstr section? The answer is here:
$ readelf --sections /bin/uptime -W
There are 30 section headers, starting at offset 0x31b8:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 0000000000000318 000318 00001c 00 A 0 0 1
[ 2] .note.gnu.property NOTE 0000000000000338 000338 000020 00 A 0 0 8
[ 3] .note.gnu.build-id NOTE 0000000000000358 000358 000024 00 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000037c 00037c 000020 00 A 0 0 4
[ 5] .gnu.hash GNU_HASH 00000000000003a0 0003a0 000044 00 A 6 0 8
[ 6] .dynsym DYNSYM 00000000000003e8 0003e8 000360 18 A 7 1 8
[ 7] .dynstr STRTAB 0000000000000748 000748 00020f 00 A 0 0 1
[ 8] .gnu.version VERSYM 0000000000000958 000958 000048 02 A 6 0 2
[ 9] .gnu.version_r VERNEED 00000000000009a0 0009a0 000070 00 A 7 2 8
[10] .rela.dyn RELA 0000000000000a10 000a10 000198 18 A 6 0 8
[11] .rela.plt RELA 0000000000000ba8 000ba8 000228 18 AI 6 24 8
As you see the .dynsym section is linked with section number 7. (remember sh_link which indicates the index of those sections that are related to the current section).
Also, the .gnu.version is linked with the 6 section which is the .dynsym.
the .gnu.version_r linked with the 7 section which is the .dynstr. In this way, you can find out where should search for the string versions.
1-12 .note* ELF section
Those sections which are from NOTE type, describe some information about the binary file. This information is sometimes used for debugging purposes.
$ readelf --sections -W ./test_data.elf
There are 31 section headers, starting at offset 0x36f8:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 0000000000000318 000318 00001c 00 A 0 0 1
[ 2] .note.gnu.property NOTE 0000000000000338 000338 000020 00 A 0 0 8
[ 3] .note.gnu.build-id NOTE 0000000000000358 000358 000024 00 A 0 0 4
[ 4] .note.ABI-tag NOTE 000000000000037c 00037c 000020 00 A 0 0 4
.note.gnu.build-id:
This section contains an identification code that is unique to the ELF file. Roland McGrath, known for his work on glibc, invented the GNU build ID 15 years ago and provided the implementation for various build tools.
The build ID is a 160-bit SHA1 string that is computed over the elf header bits and the contents of sections in the file.
Why would we want to identify a specific binary?
To match a set of debug symbols to a given binary when trying to debug.
To verify that two binaries are in fact the same build
All NOTE-type sections have the same structure:
typedef struct
{
Elf64_Word n_namesz; (4-bytes) /* Length of the note's name. */
Elf64_Word n_descsz; (4-bytes) /* Length of the note's descriptor. */
Elf64_Word n_type; (4-bytes) /* Type of the note. */
} Elf64_Nhdr;
A section note has a structure that describes its value size and then is followed by its data.
For example
$ readelf --hex-dump=.note.gnu.build-id ./test_data.elf
Hex dump of section '.note.gnu.build-id':
04000000 14000000 03000000 474e5500 ............GNU.
6bb99016 a762a662 eb786731 c510c9e5 k....b.b.xg1....
a27c5ffd .|_.
The first 4 bytes represent the size of the note name, while the next 4 bytes represent the size of the note’s descriptor, which in this case is 0x14 (20).
The last 4 bytes indicate the type of the note, which in turn has a constant value for each NOTE type section.
After these values, the total number of bytes should be 0x4 + 0x14 = 0x18 (24). The first 4 bytes represent the note name, which is “GNU” in this section (build-id) and indicates that the binary is built for GNU types OS.
The next 20 bytes represent a hash value (6bb99016a762a662eb786731c510c9e5a27c5ffd), However, in other NOTE sections, it could represent a different value. which is the build-id of the binary file.
The type value is 0x00000003, which indicates that the NOTE section type is NT_GNU_BUILD_ID.
.note.ABI-tag:
This section indicates the compatible kernel version for the ELF file.
For example:
Hex dump of section '.note.ABI-tag':
04000000 10000000 01000000 474e5500 ............GNU.
00000000 03000000 02000000 00000000 ................As before the first 4 bytes represent the size of the note name which is GNU\0 in all Linux’s binary files, while the next 4 bytes represent the size of the note’s descriptor, which in this case is 0x10 (16).
But how to calculate the descriptor value?
Based on the elf.h file, for the .note.ABI.tag, the descriptor value consists of 4 parts:
/* Defined note types for GNU systems. */
/* ABI information. The descriptor consists of words:
word-0: OS descriptor
word-1: major version of the ABI
word-2: minor version of the ABI
word-3: subminor version of the ABI
*/
/* Known OSes. These values can appear in word 0 of an
NT_GNU_ABI_TAG note section entry. */
#define ELF_NOTE_OS_LINUX 0
#define ELF_NOTE_OS_GNU 1
#define ELF_NOTE_OS_SOLARIS2 2
#define ELF_NOTE_OS_FREEBSD 3word 0 is the OS descriptor which in this case is 0x00000000, meaning that the compatible OS with this binary is Linux.
After that, the words 1,2 and 3 are major, minor, and subminor versions of the kernel which are 0x00000003 0x00000002, and 0x00000000. So the compatible kernel version for this binary is 3.2.0.
The type value is 0x00000001, which indicates that the NOTE section type is NT_GNU_BUILD_ID.
.note.gnu.property:
This NOTE section indicates some properties of the file, like the instruction set, stack size, and other properties. I skip this section.
You can see the output of the readelf:
$readelf --notes ./test_data.elf
Displaying notes found in: .note.gnu.property
Owner Data size Description
GNU 0x00000010 NT_GNU_PROPERTY_TYPE_0
Properties: x86 ISA needed: x86-64-baseline
Displaying notes found in: .note.gnu.build-id
Owner Data size Description
GNU 0x00000014 NT_GNU_BUILD_ID (unique build ID bitstring)
Build ID: 6bb99016a762a662eb786731c510c9e5a27c5ffd
Displaying notes found in: .note.ABI-tag
Owner Data size Description
GNU 0x00000010 NT_GNU_ABI_TAG (ABI version tag)
OS: Linux, ABI: 3.2.0
It’s worth noting that sections labeled as “NOTE” load in memory at runtime, as indicated by the “Alloc(A)” flag in their flags. But why is this the case? The reason is that the dynamic loader requires this information for certain checks. For instance, it uses the .note.gnu.property or .note.ABI-tag to verify whether the binary is supported by the operating system kernel, or whether the CPU supports the binary’s instruction set.
1-13 .got, .got.plt and .plt , .plt.got ELF Sections
These four sections are very important parts of an ELF file. This is because these parts work like wings when flying.
The output of the readelf shows that the type of these sections is PROGBITS and that the contents of these sections are some byte codes that should be executed in memory.
Long story short, these sections together do the dynamic loading process at the running time.
In The next part, I will focus on an examination of dynamic binding on Linux and talk about the functionality of these sections.
$ readelf --sections ./main.out -W
There are 30 section headers, starting at offset 0x39b8:
Section Headers:
[Nr] Name Type Address Off Size ES Flg Lk Inf Al
[ 0] NULL 0000000000000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 00000000000002a8 0002a8 00001c 00 A 0 0 1
[ 2] .note.gnu.build-id NOTE 00000000000002c4 0002c4 000024 00 A 0 0 4
[ 3] .note.ABI-tag NOTE 00000000000002e8 0002e8 000020 00 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000000308 000308 000024 00 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000000330 000330 0000c0 18 A 6 1 8
[ 6] .dynstr STRTAB 00000000000003f0 0003f0 00009d 00 A 0 0 1
[ 7] .gnu.version VERSYM 000000000000048e 00048e 000010 02 A 5 0 2
[ 8] .gnu.version_r VERNEED 00000000000004a0 0004a0 000030 00 A 6 1 8
[ 9] .rela.dyn RELA 00000000000004d0 0004d0 0000c0 18 A 5 0 8
[10] .rela.plt RELA 0000000000000590 000590 000030 18 AI 5 23 8
[11] .init PROGBITS 0000000000001000 001000 000017 00 AX 0 0 4
[12] .plt PROGBITS 0000000000001020 001020 000030 10 AX 0 0 16
[13] .plt.got PROGBITS 0000000000001050 001050 000008 08 AX 0 0 8
[14] .text PROGBITS 0000000000001060 001060 000211 00 AX 0 0 16
[15] .fini PROGBITS 0000000000001274 001274 000009 00 AX 0 0 4
[16] .rodata PROGBITS 0000000000002000 002000 000038 00 A 0 0 8
[17] .eh_frame_hdr PROGBITS 0000000000002038 002038 000044 00 A 0 0 4
[18] .eh_frame PROGBITS 0000000000002080 002080 000128 00 A 0 0 8
[19] .init_array INIT_ARRAY 0000000000003de8 002de8 000008 08 WA 0 0 8
[20] .fini_array FINI_ARRAY 0000000000003df0 002df0 000008 08 WA 0 0 8
[21] .dynamic DYNAMIC 0000000000003df8 002df8 0001e0 10 WA 6 0 8
[22] .got PROGBITS 0000000000003fd8 002fd8 000028 08 WA 0 0 8
[23] .got.plt PROGBITS 0000000000004000 003000 000028 08 WA 0 0 8
[24] .data PROGBITS 0000000000004028 003028 000010 00 WA 0 0 8
[25] .bss NOBITS 0000000000004038 003038 000008 00 WA 0 0 1
[26] .comment PROGBITS 0000000000000000 003038 000027 01 MS 0 0 1
[27] .symtab SYMTAB 0000000000000000 003060 000630 18 28 45 8
[28] .strtab STRTAB 0000000000000000 003690 000220 00 0 0 1
[29] .shstrtab STRTAB 0000000000000000 0038b0 000107 00 0 0 1
The difference between .plt* and .got* sections is in their content.
The .plt and .plt.got sections contain byte codes that should be run at the running time for resolving dynamic symbols. (Alloc and Execute flags).
On the other hand, the .got and .got.plt sections contain some information that should load in the process’s memory to help the .plt and .plt.got codes to resolve dynamic symbols. (Alloc and Write flags).
You can see the contents of .plt and .plt.got with the objdump. Because the content is some bytecodes you should see them with a disassembler.
$ objdump --disassemble --section=.plt ./main.out -M intel
./main.out: file format elf64-x86-64
Disassembly of section .plt:
0000000000001020 <.plt>:
1020: ff 35 e2 2f 00 00 push QWORD PTR [rip+0x2fe2] # 4008 <_GLOBAL_OFFSET_TABLE_+0x8>
1026: ff 25 e4 2f 00 00 jmp QWORD PTR [rip+0x2fe4] # 4010 <_GLOBAL_OFFSET_TABLE_+0x10>
102c: 0f 1f 40 00 nop DWORD PTR [rax+0x0]
0000000000001030 <printf@plt>:
1030: ff 25 e2 2f 00 00 jmp QWORD PTR [rip+0x2fe2] # 4018 <printf@GLIBC_2.2.5>
1036: 68 00 00 00 00 push 0x0
103b: e9 e0 ff ff ff jmp 1020 <.plt>
0000000000001040 <__isoc99_scanf@plt>:
1040: ff 25 da 2f 00 00 jmp QWORD PTR [rip+0x2fda] # 4020 <__isoc99_scanf@GLIBC_2.7>
1046: 68 01 00 00 00 push 0x1
104b: e9 d0 ff ff ff jmp 1020 <.plt>
1-14 .interp ELF Section
This section holds the path of an interpreter.
The interpreter is a program that knows how to run the binary file.
In Linux OS, this file usually is ld.
When we run an ELF executable file, the OS looks at this section to find out the dynamic loader and then uses it to resolve dynamic symbols like functions from shared libraries.
readelf --hex-dump=.interp /usr/bin/date
Hex dump of section '.interp':
0x00000318 2f6c6962 36342f6c 642d6c69 6e75782d /lib64/ld-linux-
0x00000328 7838362d 36342e73 6f2e3200 x86-64.so.2.As you can see, the content of this section is a NULL terminated string which is the path of the dynamic linker.
Conclusion
In this section, I covered ELF sections and provided a detailed explanation of section contents. In the next part, I will delve into segments and discuss the linking process during runtime.part, I will speak of segments and the linking process at the running time.

