
به نام خدا
با سلام. تصمیم گرفتم که یک مجموعه ای تهیه کنم که بتونم مفاهیم Binary Instrumentation رو به زبان فارسی توضیح بدم و بتونم یه منبعی برای این بحث توی سایتهای فارسی زبان داشته باشم. البته خب من سعی کردم توی این مجموعه جوری بنویسیم که مفاهیم تغییری درش ایجاد نشه و مطلب کاملا ساده باشه برای کسانی که میخوان خیلی ساده مفاهیم رو درک کنن. گرچه این موضوع تخصصی هست و نیاز به یک سری پیش نیازها داره ولی من سعی کردم که تا جایی که میشه توضیحات کامل بدم. امیدوارم مفید باشه
این مطالب رو توی چند بخش مینویسم و چندتا تیکه کد هم میزنم که با مثال پیش ببرم.
منابع این پست ها:
- [1] Practical Binary Analysis Book
- [2] PEBIL: Efficient Static Binary Instrumentation for Linux
- [3] Anywhere, Any-Time Binary Instrumentation
قسمت اول: معرفی و مفهوم ابزاردقیق باینری
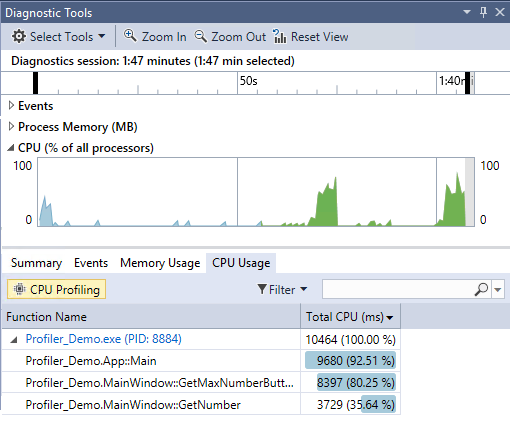
اسم این مبحث Binary Instrumentation هست که خب ترجمه اون میشه “ابزار دقیق باینری” که خب معنای تحت الفظیش میشه اندازه گیری فایلهای باینری. البته ما اندازه گیری خاصی در باینری نداریم اما میتونیم اینجوری معنیش کنیم: اندازه گیری سرعت، کارایی و خطاهای یک فایل باینری. خب این به زبان خودمونی تر میشه تحلیل و بررسی رفتار یک فایل باینری. یعنی من میخوام بدون اینکه به کد برنامه دسترسی داشته باشم، بتونم برنامه رو در زمان اجرا بررسی کنم و ببینم روند اجرای برنامه چه جوریه، از کجا به کجا میره و اگه من یه جای خاص از کد یه دستور اضافه یا کم کنم یا تغییر ایجاد کنم، توی روند برنامه چه تغییراتی ایجاد خواهد شد. به این قضیه میگن ابزاردقیق باینری. البته استفاده های مختلفی از این تکنیک میشه مثلا برای بهبود کارایی و سرعت برنامه ها، بررسی آسیب پذیری ها و امن سازی برنامه هایی که سورس کدشون به هر دلیلی در دسترس نیست و … به عنوان مثال اگر از VisualStudio استفاده کرده باشید دیدید که موقع اجرا و دیباگ کردن برنامه، شما میتونید از ابزاری به نام Profiler استفاده کنید که این ابزار در حقیقت یه “ابزار دقیق” هست برای بررسی سرعت و کارایی نقاط مختلف کد و توابع برنامه. مثلا توی تصویر پایین میبینید که توابع برنامه موقع اجرا به ترتیب زمان استفاده از CPU نشون داده شدند.
روش های پیاده سازی ابزار دقیق
خب حالا بریم سراغ اینکه این تکنیک چه جور انجام و پیاده سازی میشه؟ ساده ترین روش برای پیاده سازی یک “ابزاردقیق” برای یک فایل باینری، Patch کردن فایل باینری هست. در این روش شما خیلی ساده فایل رو Disassemble میکنید و یا دیباگ میکنید و قسمتی از کد رو تغییر میدید. مثلا یه جایی یه شرطی چک میشه رو NOP میکنید یا شرط پرش(jump) رو تغییر میدید و یه سری کارهای محدود که میشه انجام داد. ساده ترین راه این هست و خب یک سری معایا و محدودیت هایی داره که باعث میشه ما به سمت استفاده از روش های بهتر بریم. همونجور که میدونید فایلهای باینری ( در این مجموعه منظور ما از باینری، تمام فایلهای اجرایی ویندوزی، لینوکسی و مک و … است) دارای یک ساختار مشخص بیتی هست. یعنی اینکه تغییر توی یک بیت از یک فایل باینری ممکنه روند اجرا رو کاملا مختل کنه و یا اصلا فایل رو خراب کنه. پس با توجه به این مساله، تکنیک patch کردن با خیلی از محدودیت ها مواجه میشه. مثلا ما نمیتونیم هر دستوری رو با هر سایزی که خواستیم و مد نظرمون بود رو داخل فایل تزریق کنیم چونکه با این کار، دستورات ممکنه شیفت بخورن و جابه جا بشن و خب ساختار فایل خراب بشه. پس با توجه به این شرایط متوجه شدیم که Patch کردن صرفا برای انجام یک سری کارهای محدود که نیاز زیادی به تزریق کد زیادی ندارند، روش مناسبی هست ولی تو بقیه موارد اصلا مناسب نیست. حالا الان اگه بخوام به زبان خیلی ساده توضیح بدم که “ابزار دقیق” چیه، میشه گفت که “ابزاردقیق باینری” اینه که کد تزریق کنیم داخل فایل باینری و رفتارشو بررسی کنیم. حالا این بررسی میتونه از لحاظ Performance باشه یا از لحاظ امنیتی.
مثلا: فرض کنید میخوایم بفهمیم که توی روند اجرای یک فایل باینری، چند بار برنامه تابعی رو فراخوانی میکنه. خب ساده ترین راه اینه که بیایم و فایل رو دیس اسمبل کنیم، بعد تمام دستورات call یا jmp رو پیدا کنیم و قبل هر کدوم از این دستورات یک دستور مثلا inc eax بزاریم که برامون نقش یک شمارنده رو بازی کنه.( البته بگم که این کاری که الان گفتم اصلا اصولی نیست چونکه اگه بخوایم به register ها اعتماد کنیم سخت در اشتباهیم. چونکه ما نمیدونیم اون register کجاها تغییر میکنه. اما اینجا فقط برای بحث آموزش گفتم) و در انتها بیایم eax رو بخونیم و اونموقع میفهمیم که چندتا تابع اجرا شده و در حقیقت برنامه چند بار از call یا jmp استفاده کرده. خب این کار خیلی ساده بود گرچه کلا کار اشتباهیه اما چندتا محدودیت داریم. یکی اینکه شاید بخوایم یه بررسی پیچیده تر انجام بدیم یا طول کدی که میخوایم تزریق کنیم داخل برنامه زیاده و باعث به هم ریختن ساختار فایل میشه. بخاطر همین مشکلات پلتفرم هایی ساخته میشن برای “ابزاردقیق باینری”.
خب این تیکه رو توضیح دادم که با اصل قضیه آشنا بشید و بریم سراغ موارد پیشرفته تر.
ما کلا 2 تا روش یا پلتفرم کلی برای انجام و ایجاد ابزار دقیق داریم:
- روش ایستا یا Static
- روش پویا یا Dynamic
که هر کدون از این روش ها مزایا و معایب خودشون رو دارند. که در ادامه بهشون میپردازم.
روش ایستا یا Static:
در پلتفرم ایستا، دقیقا عین کاری که توی Patch کردن بود، استفاده میشه با این تفاوت که پیشرفته تر هست و احتمال خطا و تخریب فایل باینری رو به حداقل میرسونه. توی این روش فایل باینری بازنویسی میشه و در حقیقت کدهای فایل رو برمیداره و کدهای جدید و مربوط به ابزار دقیق رو داخلش قرار میده و بعد توی یک فایل جدید بازنویسی میکنه. یعنی rewrite و relocate میکنه. همونجور که میدونید فایل های باینری دارای Section ها یا بخش های مختلفی هستند که داده ها و کدها داخلشون ذخیره میشن. حالا این پلتفرم های ایستا کد رو که تغییر میده، میاد و کد جدید رو توی یک فایل جدید با Section های جدید و بازنویسی شده ذخیره میکنه. اینجوری کدهای برنامه overwrite نمیشه و ساختار فایل هم خراب نمیشه. در اصل مثل این میمونه که اینها یک فایل رو از اول کامپایل کنند. این تغییرات روی دیسک ذخیره میشه.
روش پویا یا Dynamic:
از اون سمت، پلتفرم دیگه، روش پویا هست که برعکس روش قبلی، این روش هیچ کاری با فایل باینری نداره و نه چیزی بهش اضافه میکنه و نه تغییری درش ایجاد میکنه. بلکه موقع اجرا میاد و توی رشته کدهای برنامه که در حال حرکت به سمت CPU هستند برای اجرا، کدهای مربوط به ابزار دقیق رو تزریق میکنه. یعنی هیچگونه تغییری توی فایل یا Section مربوط به کد باینری ایجاد نمیشه. تمام تغییرات توی رشته کدی که به سمت CPU میرن برای اجرا، انجام میشه. پس توی این روش ما هیچ نگرانی بابت خراب شدن فایل نداریم. اما این روش یک مشکل داره و اونم اینه که چون به صورت پویا یا dynamic کد رو مانیتور میکنه و کدهای جدید رو تزریق میکنه، باعث میشه سرعت اجرای برنامه به شدت تحت تاثیر قرار بگیره و چیزی حدود 4 برابر سرعت اجرا رو کم کنه.
توی کتاب Practical Binary Analysis یه مقایسه ای بین این دوتا پلتفرم کرده. البته اینو بگم که ما اینجا قصد بررسی ابزارها رو با هم نداریم. صرفا داریم در مورد متدها و مزایا و معایبشون صحبت میکنیم.
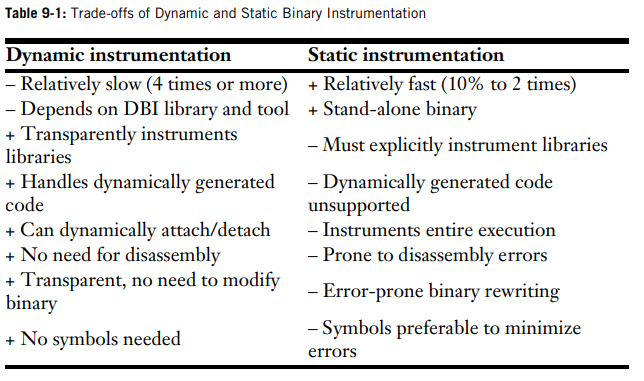
خب همونجور که مشخصه سرعتشون خیلی باهم فرق داره و ما توی روش ایستا با وجود تمام محدودیت هایی که داره ولی سرعتش به طور قابل ملاحظه ای بالاست.
حالا میخوایم تو قسمت بعدی در مورد هر کدوم از این روش ها صحبت کنیم که بگیم چه جور کار میکنن و تو هر مرحله هم یه نمونه پیاده سازی داشته باشیم.
بررسی روش های موجود در ابزاردقیق ایستا یا Static Binary Instrumentation (SBI) :
خب همونجور که بالاتر گفتم، توی این روش به صورت ایستا فایل باینری تغییر میکنه. به عبارتی فایل روی دیسک تغییر میکنه یعنی تغییر واقعیه و به محتویات فایل اضافه میشه. حالا چه جور این کار انجام میشه رو بالاتر یه مقدار توضیح دادم ولی الان میخوام کاملا تکنیکش رو توضیح بدم که تو عمل چه اتفاقی میافته:
خب فرض کنیم که تیکه کد زیر رو داریم و میخوایم که بفهمیم مقدار Eax که همون آرگومان ورودی تابع test_func هست چیه و اونو چاپش کنیم توی خروجی.( اینجا خیلی ساده میخوام مفهوم رو برسون وگرنه در عمل همچین چیزی اصلا پیاده سازی نمیشه). خب خیلی راحت راهکاری که استفاده میشه اینه که بیایم و قبل از اینکه اون call به تابع اتفاق بیافته، مقدار eax رو چاپ کنیم. خب برا این کار ببینید ما نیاز داریم تا یک سری دستور جدید به فایل باینری اضافه کنیم که خب برا اینکه ما ساختار فایل و کد رو بهم نریزیم طبق چیزی که بالا گفتم، مجبوریم کد ابزار دقیق رو منتقل کنیم یک جای جدید و اونجا انجام بدیم.

اینجا یه نکته بگم: ما توی ابزاردقیق باینری، دوتا مفهوم داریم که مهمه: 1- محل انجام ابزاردقیق(instrumentation point) 2- کد ابزاردقیق (instrumentation code) اینجا به اون خط 5 ام که قراره ابزاردقیق روش انجام بشه، میگیم محل ابزاردقیق یا Instrumentation point و کد ابزار دقیق هم که مشخصه اون کدی هست که برا انجام ابزاردقیق مینویسیم که این تیکه بالا سمت راست میشه.
خب ببینید برای این کار میشه اومد و به جاای اون دستور push eax توی کد اصلی، یک دستور jmp گذاشت به یک تیکه کد جدید و داخل اون تیکه کد عملیات ابزاردقیق رو انجام داد و بعد برگشت به روال عادی برنامه. همونطور که توی عکس مشخصه اول از همه نیازه که وضعیت فعلی برنامه ذخیره بشه. منظور از وضعیت فعلی، یعنی تمام محتوای Register ها و فلگ ها و Call stack . چونکه ممکنه به هر حال عملیات ابزاردقیق ما تغییراتی رو توی Register ها به وجود بیاره و باعث مختل شدن روند ادامه برنامه بشه. پس به خاطر همین از pusha مثلا استفاده شده که وضعیت فعلی برنامه ذخیره بشه. بعد اومدیم و مقدار eax که اینجا ورودی تابع test_func هست رو فرستادیم داخل تابع printf که چاپ بشه و بعد هم که کار تموم میشه میایم و وضعیت Register ها رو برمیگردونیم به حالت قبل با popa و روال برنامه رو با jmp برمیگردونیم به روال اصلی.
خب تا اینجا همه چی درسته و این متد در ظاهر جواب میده. اما اینجا یه مشکل بزرگ داریم که این راه رو برامون غیر ممکن میکنه.
ببینید توی تصویر بالا وسط، ما اومدیم و به جای push eax ، یه دستور jmp گذاشتیم ولی به یک نکته توجه نکردیم که این کار فقط روی کاغذ شدنیه چونکه سایز دستور push eax ، کلا 1 بایت هست و دستور jmp که ما میزاریم 5 بایت هست. یعنی ما 4 بایت داریم کد برنامه رو شیفت میدیم که این باعث میشه اصلا ترتیب کدها به هم بخوره و ساختار فایل بهم بریزه و اصلا اجرا نشه. پس این روشی که گفتیم روی کاغذ روش خوبیه و پلتفرم های SBI میتونن ازش استفاده کنن اما، نه به این صورت که ما گفتیم چونکه ما نیاز داریم تا حداقل 5 بایت برای یه jmp فضا داشته باشیم تا بتونیم کد رو منتقل کنیم به یه جای دیگه. مشکل این روشی که ما گفتیم دقیقا همین سایز هست. پس باید یک متدی باشه که بدون آسیب زدن به ساختار فایل و بدون ایجاد خطا در کد بتونه بستر ابزاردقیق ایستا رو فراهم کنه که در ادامه توضیح میدم که اکثر SBI ها از چه متدی استفاده میکنن.
راه حل های موجود برای SBI :
توی [2] که در مورد PEBIL که یکی از معروف ترین SBI های برای لینوکسه، اومده راهکارهای موجود رو گفته که من این راه ها رو از اونجا خوندم و اینجا مینویسم:
روش Trampoline :
این روش میگه که بیایم و jmp های کوچک با سایز کمتر بزاریم و هی از این jmp به اون jmp بریم تا بلاخره برسیم به یه جایی که بشه 5 بایت پیدا کرد و jmp اصلی رو گذاشت. مشکل این روش این هست که ما توی معماری x86 کمترین سایز jump ی که داریم، 2 بایت هست و ما دستوراتی رو توی کد ممکنه داشته باشیم که سایزشون 1 بایته مثل همین مثالی که بالا زدیم. پس اینجا بازم مشکل بزرگتر بودن سایز دستور رو داریم.
روش int3:
توی این مقاله یه راهی رو گفته که خب دیباگرها ازش استفاده میکنن و اونم استفاده از وقفه نرم افزاری شماره 3 هست که همون opcode مربوط بهش میشه 0xcc. دیباگرها دقیقا از همین تکنیک استفاده میکنن برای Breakpoint ها توی برنامه. زمانی که شما روی یه دستور توی باینری یه Breakpoint میزارید در حقیقت دیباگر میاد و ابتدای اون دستور رو با 0xcc بازنویسی میکنه و وقتی سیستم عامل به این دستور خورد یه وقفه تولید میشه که خب اونجا دیباگر میفهمه که برنامه رسیده به اون خط. حالا اینجا میگه که میشه از این روش استفاده کرد و جاهایی که سایز دستور کمه و فضا نیست براش بیایم و از این وقفه استفاده کنیم. خوبیه این روش اینه که این وقفه شماره 3 دقیقا سایزش 1 بایت هست و همه جا میشه ازش استفاده کرد دقیقا به خاطر سایز کم. اما یه سربار زیادی این روش داره و اونم اینه که ما باید یه Execption handler بنویسیم که همون کد instrumentation رو اجرا میکنه و وقتی این وقفه اجرا میشه، اون EH بیاید و اجرا بشه. این سربار باعث میشه که این روش خیلی کند کار کنه.
روش relocation and reorganization:
توی این روش که تو این مقاله[2] گفته و این ابزار PEBIL ازش استفاده میکنه راه خیلی مناسب و بدون خطا و پر سرعتی رو ابداع کرده.
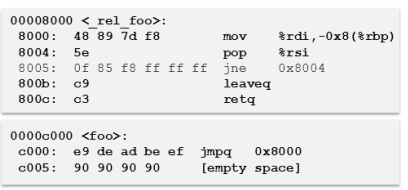
این روش اینجوریه که میاد و تمام اون تابعی و یا Basic Block ی که قراره ابزاردقیق داخلش اجرا بشه رو کلا منتقل میکنه به یک قسمت جدید داخل فایل باینری، و ابتدای اون تابع توی قسمت اصلی کد، یک jump میزاره و کلا اون تابع رو بازنویسی و باز سازماندهی میکنه. توی این حالت دیگه اصلا نگرانی بابت اینکه آیا به اندازه کافی برای یه jump فضا باشه، نیست و راحت میشه هر تعداد دستور با هر سایزی رو توی برنامه جا داد. برای درک بهتر این عکس پایین که از همون مقاله هست رو گذاشتم که توضیحات رو روی عکس بدم
خب بینید ما الان یک تابع به نام foo داریم که میخوایم اینو عملیات ابزاردقیق روش پیاده سازی کنیم. این تابع تو حالت عادی توی فایل باینری به این شکله:
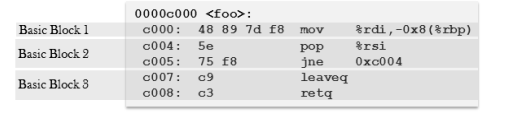
حالا این اگه بخوایم بر اساس متد این PEBIL بریم جلو باید ابتدا عین این کد تابع رو منتقل کنیم به یک section جدید توی فایل باینری و در حقیقت یک Section جدید بسازیم. یک Code Section جدید و کد این تابع رو منتقل کنیم اونجا و سپس ابتدای تابع اصلی رو یه jump بزاریم که روال برنامه رو منتقل کنه به مکان جدید تابع توی section جدید:
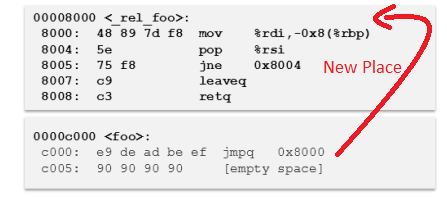
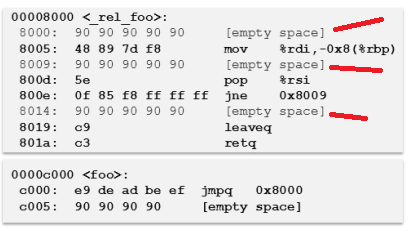
خب همونطور که میبینید تابع رو بازنویسی کرده و اسمشو گذاشته _rel_foo و از اونطرف توی Section اصلی اومده و ابتدای تابع یک دستور jump گذاشته که روال رو منتقل کنه به مکان جدید تابع. حالا تا اینجا فضای کار باز تر شده و راحت تر میتونه کد تزریق کنه. چون Section جدیدی که ساخته ، سایزش رو میتونه هر چقدر که نیاز داشت تغییر بده. توی مرحله بعد برا اینکه یه نرمال سازی و استانداردسازی انجام بشه و همه دستورات jump تبدیل بشن به 5 بایتی، میاد و یه padding انجام میده. این به خاطر این هست که اگر خواست روی jump ها یه ابزاردقیق انجام بده، مطمعن بشه که اون jump سایزش 5 بایت هست و راحت بتونه بازنویسی کنه. مثلا ببینید توی عکس بالا دستورjne یه پرش 2 بایتی هست که خب اگه یه موقع نیاز شد این رو ابزاردقیق کنه، اینجا به مشکل میخوره چون این پرش 2 بایتیه. پس میاد همه پرش ها رو تبدیل میکنه به نوع 5 بایتی تا این مشکل پیش نیاد. عکس پایین بعد از انجام اون padding هست:
خب حالا کد به اصطلاح relocate شده و padding هم روش انجام شده. حالا میاد و قبل از هر BasicBlock توی این section جدید یک سری nop میزاره به عنوان یه جور فضای رزرو شده برای اینکه اگه خواست ابزاردقیقی اضافه کنه، اون فضا رو داشته باشه.
خب حالا مثلا ببینید اومده و قبل از هر بیسیک بلاک 5 بایت nop رو گذاشته به عنوان فضای رزرو برای ابزاردقیق. مثلا فرض کنید میخوایم اون دستور اول تابع که mov هست رو ابزاردقیق براش ایجاد کنیم. خب ببینید:
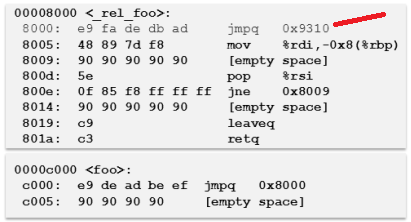
همونجور که میبینید اومده یه jump گذاشته قبل از این دستور mov و منتقل کرده توی تابع instrumentation که ابزاردقیق رو اونجا نوشته و بعد که کارش تموم شده روال رو بر میگردونه به ادامه کار. در واقع اگه الان بخوام بهتون نشون بدم که فرایند اجرای کد چه جوری میشه توی این تابع، به اینصورت که ت عکس پایین میبینید از 1 تا 4 اجرا میشه و ابزاردقیق هم اجرا میشه :
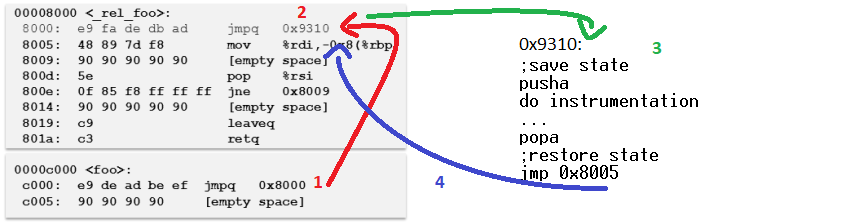
خب الان طبق تصویر بالا الان یه فایل باینری داریم که ساختارش تغییر کرده و تابع foo تو محل اصلی خودش نیست و منتقل شده به یک ادرس جدید و به جاش یه دونه jump گذاشته به آدرس جدیدش. حالا برنامه اجرا میشه، تابع foo فراخوانی میشه (1) بعد روال برنامه منتقل میشه به آدرس جدید. اونجا خواسته که یه ابزاردقیق انجام بشه قبل از دستور mov که خب یه jump گذاشته به کد ابزاردقیق یا همون instrumentation code که روال برنامه منتقل میشه(2) اونجا اول وضعیت برنامه ذخیره میشه، ابزاردقیق انجام میشه (3) و در آخر برمیگرده به روال عادی (4).
خب این متدی هست که اکثر ابزارهای ابزاردقیق ایستا یا SBI انجام میدن که بهش میگن relocation یا rewriting. اینجا من فقط خواستم به عنوان مثال یک تابع رو بگم ولی در واقع، کل توابع موجود توی فایل باینری اعم از اونایی که ابزاردقیق بشن یا نشن، همه بازنویسی میشن.
حالا یک سری چالش ها این روش داره که خب حل شده و من نمیخوام اینجا در موردش صحبت کنم. مثلا پرش ها یا فراخوانی های غیر مستقیم یا همون indirect calls and jump رو توی حالت static چه جور میشه هندل کرد. خب این روش که گفتیم راهکاری که برا این قضیه ارایه میکنه اینه: به این صورت که میاد و تمام توابع برنامه رو rewrite و relocate میکنه.پس با این حساب هر جایی که یه jump یا call غیر مستقیم وجود داشت، مطمعن میشه که اون تابع هدف، بازنویسی شده و منتقل شده به یه جای دیگه.
خب چندتا ابزار که کار SBI رو انجام میدن معرفی میکنم:
- Dyninst : این فریمورک یکی از قوی ترین های ابزاردقیق باینریه که یه سری ویژگی های خوب داره که یکیش اینه که multiplatform هست. هم فایلهای PE ویندوز رو پشتیبانی میکنه هم فایلهای ELF لینوکس رو و جدیدا هم برای معماری ARM هم اومده. از ویژگی های دیگش میشه گفت که این فریمورک همزمان هم میتونه SBI انجام بده هم DBI
- PEBIL: این فریمورک هم برای ابزاردقیق هست ولی فقط از متد ایستا پشتیبانی میکنه و یه مشکلی که داره اینه که بر خلاف اسمش، فقط برای فایلهای elf لینوکسی هست. تکنیکی که بالا توضیح دادم هم برای این فریمورک هست.
خب این بخش فقط خواستم یه مروری روی روش ها بکنم و بگم اصلا ابزاردقیق چی هست. توی بخش بعدی در مورد روش پویا مینویسم و ابزارهایی که هست برای اون بخش رو هم معرفی میکنم.


Very interesting subject, appreciate it for posting.Expand blog